近日,中国新就业形态研究中心发布了《城市出行的就业韧性:网约车司机就业图景与职业表现(2025)》报告。该报告对网约车司机的收入、工作体验、保障体系等多个维度进行了系统性的分析。
报告显示,网约车司机的月平均收入为7623元,在六类主要蓝领职业(网约车司机、外卖员、货车司机、快递员、制造业普工、建筑工)中,位列第二,仅次于货车司机。其中,在一线城市,日均工作8小时以上的网约车司机,其平均月收入更是高达11557.1元。
与收入水平相对应,网约车司机的收入满意度也相对较高。
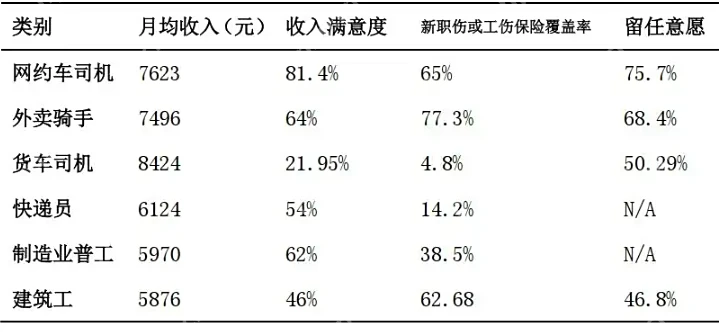
除了收入,报告还对不同蓝领岗位的工作体验进行了比较。
工作时间:网约车工作因其工时的高度弹性而备受青睐。仅有50.3%的网约车司机认为自己“工作时间长”,这一比例在建筑工中则高达85.1%。
绩效与认可:超过77%的网约车司机表示,可以通过平台的“透明账单”清晰地了解自己的收入和抽成比例。相比之下,超过75%的货车司机则常常担心货主会拖欠运费。
成长与职业机会:网约车司机的安全培训覆盖率高达95%,其继续从事该职业的意愿也达到了最高的75.7%。
综合来看,网约车司机这一职业的“净付出”(即工作要求与工作资源的比较)属于中等偏低的水平。

这份基于全国13个省市、5400多位网约车司机的调查报告还揭示,有高达77%的司机,是在失业后才转行进入了网约车行业。这表明,网约车平台已成为吸纳传统岗位流失者、稳定社会就业的重要“蓄水池”。
报告还显示,网约车司机的平均年龄约为39.8岁,整体呈现出“中年化”的特征。其中,超过六成的司机是家庭中唯一的就业人员,超过一半是家庭的主要收入来源。这也是他们更倾向于选择这种收入可即时结算、工作时间相对灵活的工作模式的重要原因。
以上就是最新报告揭示网约车司机就业图景:月均收入7623元,位列蓝领职业第二的详细内容,更多请关注php中文网其它相关文章!